
Un énorme billet de blog dans lequel je voudrais vous partager les outils / ressources / guides qui me sont utile dans mon travail en tant que chercheur. Si vous n’êtes pas chercheur, vous aurez peut-être 2 ou 3 billes pour améliorer votre productivité. Si vous êtes un chercheur aguerri aussi mais ça ne sera pas les mêmes.
Si vous êtes jeune chercheur ou chercheur en devenir, c’est le genre de guide que j’aurais aimé avoir avec moi.
Notez que ce guide est en construction. n’hésitez pas à me contacter si vous utilisez des outils que je n’ai pas mentionné et qui vous aident dans votre travail de recherche.
Logiciel
C’est à ce moment qu’il faut que je vous dise que je n’ai travaillé que sur Windows, je ne connais pas du tout ni l’écosystème Apple ni linux et je n’ai pas envie de les connaitre. Globalement, je crois que si vous avez Apple, vous pouvez passer en grande partie cette section. Si vous avez linux je suis désolé pour vous, vous avez toute ma compassion.
Flow Launcher
Le logiciel qui m’a sauvé la vie, c’est Flow Launcher. Si vous avez un mac vous avez raison de croire que Windows est un écosystème pourri parce qu’il manque Spotlight. Ben Flow Launcher, c’est un spotlight encore plus puissant.
Imaginez donc une barre de recherche windows mais qui 1) faire une recherche instantanée 2) le fait sur vos dossiers et fichiers ordinateurs ET sur internet, 3) peut faire des calculs, appeler chatgpt et faire plein d’autres trucs. Depuis que j’ai flow launcher, je n’utilise plus de raccourcis sur le bureau, je ne vais plus jamais dans le menu démarrer ni n’ouvre mon navigateur pour faire une recherche google. Chaque minute qui passe sur mon ordinateur je gagne 30 secondes sur ce que je fais par rapport à si je n’utilisais pas flow launcher. Je ne comprends même pas comment font les gens qui n’utilisent pas Flow Launcher.
A noter que pour profiter de Flow Launcher, il faut auparavant installer Everything sur votre ordinateur, puis l’ajouter en plugin sur flow launcher
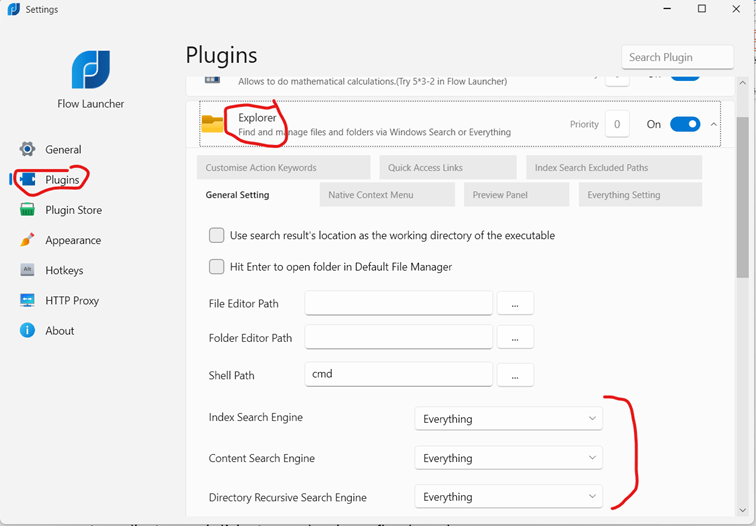
Flow Launcher : https://www.flowlauncher.com
Everything : https://www.voidtools.com/
UniGetUI
En second, je conseille fortement UniGetUI
Sur les smartphones, quand vous voulez téléchager des nouvelles versions des logiciels, vous allez sur le store dans la rubrique téléchargement puis vous télécharger les nouvelles versions. Vous pouvez même demander au téléphone de le télécharger automatiquement. Sur windows, vous ouvrez votre application et OH SURPRISE « une nouvelle version est disponible ». Au mieux vous devez cliquer sur le popup pour utiliser le logiciel, au pire vous n’aurez pas d’autre choix que d’installer le logiciel et vous perdrez 10 minutes de productivité. Bon tout ça c’est finit avec UniGetUI. Pour faire simple, ça marche exactement comme sur les smartphone : le logiciel détecte tous les logiciels et autres disponibles sur votre ordinateur, toutes les mises à jour et les met à jour automatiquement, tous d’un coup et sans devoir chercheur les mises à jour par vous-même sur internet. Incroyable.
https://www.marticliment.com/unigetui/
Glary Utilities
Si vous aviez, dans le passé, utilisé CCleaner, Glary est pareil en mieux (et avec un peu moins de pub). En gros, Glary vous permet de facilement faire de la place sur votre ordinateur, gérer les applications qui se lancent au démarrage (et fait donc démarrer votre ordinateur plus rapidement), nettoyer le registre etc. Le genre de logiciel à utiliser tous les deux-trois mois pour garder votre ordinateur puissant et vigoureux.
PDFgear
Vous voulez signer un pdf ? le transformer en image, en document word (et vice-versa) ? le scinder ou en fusionner deux ? Avant de conaitre PDFgear, j’allais sur internet, je cherchais des sites foireux qui proposent de le faire en échange de votre adresse mail pour vous spammer et tout. Depuis que j’ai PDFgear, j’ai désinstallé adobe acrobat et consort (sachant que pour lire rapidement un pdf, Edge est très agréable à utiliser), et j’utilise PDFgear dès qu’il faut remplir un document ou transformer un pdf en entre chose. Très, très utile tant que ce format du diable continuera d’être utilisé.

J’en profite pour vous donner une astuce qui change la vie. Plutôt que de copier coller du texte de PDF sur word qui se casse et qui se coupe et qui fait n’importe quoi qu’il faut réaligner toutes les lignes, transformez le pdf en word avec PDFgear, puis copier coller du word vers le word que vous utilisez. Un gain de temps de formatage absolument énorme.
Zotero
Puisqu’il faut toujours faire découvrir les classiques, Zotero est un gestionnaire bibliographique. Vous l’installez sur votre ordinateur, vous créez un compte, vous installer un addon sur votre navigateur web (disponible sur tous les navigateurs) et quand vous lisez un article en ligne, vous cliquez sur l’addon et il le range dans votre bibliothèque. Une fois que vous avez tous vos articles sur zotero, vous exportez la bibliothèque et OP, vous avez toutes vos références automatiquement écrite pour vous. Sur Word, overleaf et typst, vous avez aussi des addons qui vous permette d’automatiser encore plus les références.
Logiciel de statistique
De manière générale, je conseille aux jeunes chercheurs d’utiliser des logiciels libres : ils sont peut-être moins facile à utiliser (mais c’est le meilleur moment pour apprendre), cependant, au final, ils seront plus flexibles par rapport aux analyses que vous voudrez faire et aux figures que vous voudrez produire, vous les aurez disponible toute votre vie (contrairement aux logiciels payants qui ne marcheront plus si on ne les paye plus) et vous comprendrez mieux ce que vous faites.
Le logiciel le plus simple et gratuit est Jamovi pour les analyses fréquentistes, et Jasp pour les analyses bayésiennes. De mon côté, je vous conseille fortement R et Rstudio. Dans cette partie, je vous explique comment j’ai configuré Rstudio, dans une autre partie, je vous parlerai des packages et du code que j’utilise fréquemment :
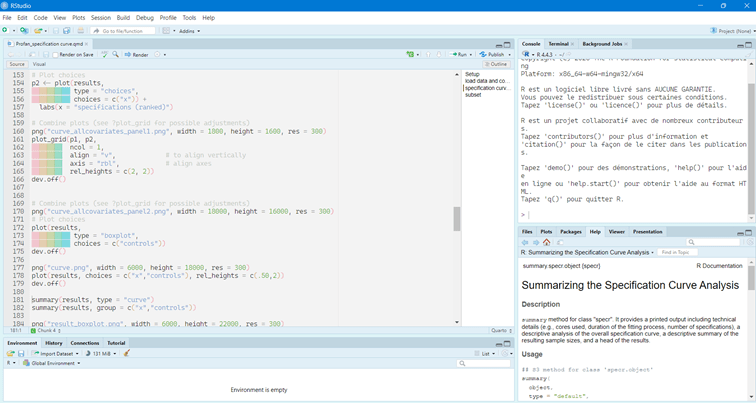
En premier, j’ai réorganisé la fenêtre de Rstudio. Clairement, la partie la plus utilisée est le script, et les parties les moins utilisées l’environnement et la console.
Ainsi, j’ai mis le script en haut à gauche, et j’ai « caché » l’environnement en bas. J’ai réduit la console à droite et j’ai laissé l’aide à droite parce que je l’utilise assez souvent.
Pour faire ce changement : tool -> global option -> pane layout
En parlant de global option, veuillez bien à DECOCHER l’option de workplace. En tant que chercheur, on ne veut jamais enregistrer les rdata car les chercheurs qui voudraient reproduire notre résultat ne le pourraient pas. Il y a des cas où l’on veut enregistrer notre environnement, mais dans ce cas on peut le faire à la main :
save.image(« environnement.RData »)
load(« environnement.RData »)
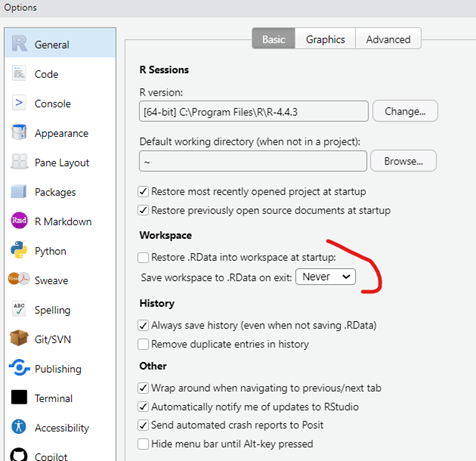
Concernant le reste des ajustements, j’ai mis dans code -> display -> « indentation guide : rainbow fills » qui me permet de plus facilement voir l’indentation
Dans appearance j’ai mis les paramètres suivants :
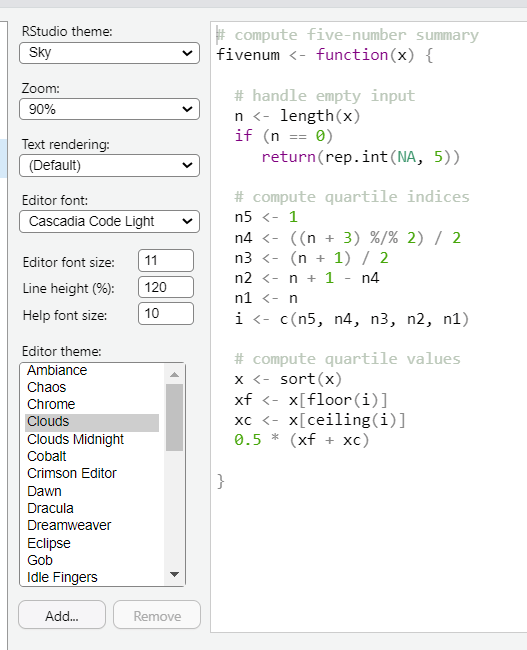
Ce ne sont pas forcément des paramètres optimaux parce que je n’ai pas les mêmes sur mon écran 32 pouces (sur celui avec ces paramètres, l’écran est de 15 pouce). Généralement il faut bien distinguer les commentaires du code par une couleur différente, bien distinguer les mots entre parenthèses de ceux qui n’en sont pas et les nombres des textes. Le thème clouds le fait pas trop mal mais d’autres seront peut-être plus à votre goût. Ce qui va beaucoup changer entre les personnes c’est surtout la taille du texte. De mon côté, j’aime avoir un texte assez petit pour avoir une bonne vision globale du script, mais pas trop petit pour ne pas me tromper de ligne quand j’écris. Et la taille du texte change avec l’écran donc il faudra jongler en fonction de votre confort.
Dernier point mais pas des moindres, les raccourcis. De mon côté, j’utilise beaucoup les raccourcis par défaut, mais j’ai changé les suivants :
Comment/uncomment : j’ai remplacé par control + shift + c sur un ordinateur, control + q sur le second (oui je suis bizarre). C’est un raccourci qu’on utilise beaucoup, prenez le temps de trouver la commande qui vous plait le plus.
Insert pipe operator : obligatoire quand vous utilisez le tidyverse, j’ai mis control + shift + m. de très loin le raccourci que j’utilise le plus.
Insert Chunk : comme je vais l’expliquer plus bas, j’utilise principalement Quarto. Insérer un chunk est donc extrêmement utile. J’ai mis control + alt + i de mon côté.
Pour le reste il y a évidemment le control f pour recherche, control z pour revenir en arrière etc…
Voilà pour le paramétrage.
Editeur de texte
Evidemment, tout le monde pense à Word quand il s’agit d’éditeur de texte. De mon côté, j’en ai testé plein, des complexes, des moins complexes, des minimalistes, des libres, des payants, des en ligne. J’aurais aimé essayé une machine à écrire mais j’ai pas l’ocassion (me contacter si vous en avez une fonctionnelle).
Par rapport à votre choix d’éditeur de texte, le principal argument va être de savoir AVEC QUI vous allez travailler. L’immense majorité des chercheurs en psychologie ne connaissent que Word. En économie, beaucoup de chercheurs écrivent en LateX, principalement sur Overleaf. Et vous ne voulez pas écrire 20h un mémoire sur LateX pour que votre directeur de mémoire vous dise qu’il y comprend rien et qu’il préfère une version word.
Le problème de Word c’est que dès qu’il s’alourdit (parce qu’on a beaucoup de pages, parce qu’on met beaucoup d’images), il devient super lent à se lancer et à naviguer. Et je n’aime pas attendre. Le problème d’Overleaf, c’est qu’il utilise une version basique de LateX, extrêmement personnalisable, mais qui amène plein de bugs, d’erreur et avec des messages d’erreur obscurs. Le problème de Quarto, c’est qu’il nécessite d’utiliser un logiciel -Rstudio et à chaque fois qu’on aura des cas particuliers (genre des sous-tables ou je ne sais pas quoi), on sera bloqué. J’ai donc choisi un entre deux – Typst.
Typst est à la fois un système d’écriture et un site internet qui permet d’écrire des articles. Contrairement à word (et comme overleaf), Typst ne charge pas immédiatement les images et le texte et permet donc d’écrire instantanément. De plus, il lie le référencement à la bibliographie ce qui permet d’éviter (comme sur word) d’avoir des citations dans le texte qui ne sont pas en bibliographie et vice-versa. Un gain de temps énorme quand le texte est finit et qu’il faut regarder à la main que la bibliographie est bien mise. Et contrairement à Overleaf, la création d’image et de tableau n’est pas horriblement difficile à coder (c’est plus compliqué que sur word mais ce n’est pas infaisable). Enfin, Typst permet de facilement télécharger une version pdf (comme overleaf) MAIS AUSSI une version word. Et ça c’est cool quand faut collaborer avec des gens qui ne jurent que par word.
Maintenant, si vous vous demandez si ça vaut le coup d’apprendre LateX, je dirais que pas forcément. Plein de chercheurs ont fait carrière sans même savoir ce qu’est LateX. Si vous êtes proche du domaine économique, ça vaut peut-être plus le coup. De mon côté, si vous me laissez le choix entre utiliser Overleaf, Typst ou Word, mon choix ira sans aucun doute à Typst mais je comprends les personnes qui restent sur Word.
Les sites internet
Extensions
Concernant le navigateur internet, j’utilise firefox (une version appelée zen browser). J’aime beaucoup le navigateur ARC mais qui n’était pas assez stable la dernière fois que je l’ai installé. Pour la lecture de PDF ou l’utilisation de copilot, j’utilise Edge (Depuis Trump, j’ai arrêté d’utiliser Copilot pour utiliser le chat de mistral).
Au niveau des extensions, j’utilise unpaywall, une extension permettant de souvent (je dirais environ 30% du temps) de trouver l’article en version libre d’accès.
J’utilise l’extension pubpeer qui me prévient s’il y a des commentaires sur un article qui pourrait remettre en question ses résultats.
J’utilise Languagetools pour la correction de langage. J’en ai essayé plusieurs et après avoir passé quelques années sur grammarly, j’ai changé pour languagetools et j’en était tellement satisfait que j’ai payé pour avoir toutes les fonctionnalités. Il propose de corriger les mots, mais aussi de trouver des synonymes et utilise l’IA pour changer des bout de phrase. Moi j’aime beaucoup et je trouve ça très simple d’utilisation. A noter que contrairement aux concurrents, il n’est pas américain mais Allemand.
Anna’s archives (les archives d’anna)
Je ne recommande pas DU TOUT (n’y allez surtout pas) ce site internet permettant de lire de nombreux livres, dont des livres scientifiques, en anglais mais aussi en français.
Latex Tables
De niche, j’en conviens, mais ceux qui galère apprécieront. Un site permettant de copier coller un tableau word et de le transformer en tableau Latex ou Typst ou autre.
Feedly
Si vous vous demandiez comment je trouve les articles que je vulgarise dans ma newsletter, la moitié viennent de feedly, l’autre de bluesky. Feedly est un aggrégateur de flux. On y ajoute les flux des journaux qui nous intéresse, et dès qu’un nouvel article est publié dans le journal, il est ajouté à feedly.
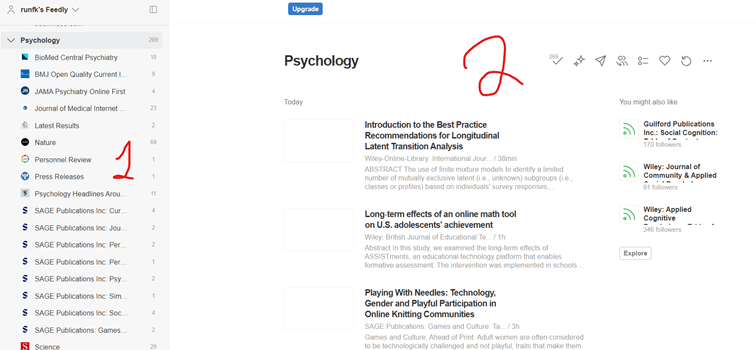
A gauche (1) se trouvent les journaux auxquels je suis abonné, à droite (2) les articles publiés cette semaine. Je lis le titre, s’il me plait je lis l’abstract et si ça me plait aussi je clique dessus pour lire l’article complet.
Images de présentation
Pour avoir des belles images d’illustration pour les présentations, j’utilise Unsplash : https://unsplash.com/fr. Pour le reste, je trouve que l’outil de powerpoint (insertion –> image -> image en ligne) fonctionne très bien, en plus de l’outil icônes.
Calcul taille d’effet
Pour calculer les tailles d’effet sur R, le package MOTE fonctionne très bien. Il existe cependant une shiny app (un site internet) qui permet de le faire sans code : https://shiny.posit.co/r/gallery/life-sciences/mote-effect-size/
The 100%CI
Tenue par Anne Scheel, Ruben Arslan, Malte Elson et Julia Rohrer, the 100%Ci est un blog qui parle de pleins de trucs intéressants sur le fonctionnement des statistiques en psychologie, comme – faut-il exclure les répondants qui ne passent pas les questions de compréhension, Que signifie un intervalle de confiance à 95%, Quand dire qu’un effet est causal, etc.
The 20% Statistician
Apparemment, il faut avoir un pourcentage dans son titre pour être cool. Ce blog est tenu par Daniël Lakens et va plutôt discuter des pratiques de recherches, que cela soit l’utilisation de l’analyse de puissance ou le pré-enregistrement.
https://daniellakens.blogspot.com/
MGTO – Gilad Feldman
Le site internet que j’ai probablement le plus visité en tant que chercheur. Gilad a créé des dizaines de guides et de modèles. On y trouve par exemple un guide d’utilisation de Jamovi et Jasp, de R, de création d’articles de réplications, mais aussi de création d’articles de méta-analyses (ceux-là, c’est moi qui les ai écrits), des guides pour transformer les tailles d’effets entre eux, d’utilisation de Qualtrics ou encore de peer-reviewing.
Common statistical tests are linear models (or: how to teach stats)
Un des sites internet qui m’a le plus changé ma manière de penser les statistiques. Il explique point par point pourquoi les tests t, les anova, ou les tests de Chi² sont juste des variations de régressions linéaires.
https://lindeloev.github.io/tests-as-linear/
Une introduction aux modèles hiérarchiques (ou multiniveaux)
Depuis quelques années, les modèles multiniveaux remplacent progressivement les ANOVA à mesure répétées. Souvent parce que les chercheurs font n’importe quoi comme ne prendre en compte que le random intercept. Cette visualisation permet de comprendre comment ces modèles fonctionnent.
http://mfviz.com/hierarchical-models/
Notez que si vous voulez un guide d’utilisation, je recommande l’article suivant de Nicolas Sommet et Davide Morselli, d’une simplicité de compréhension incroyable et en plus avec les 2be3 dedans : https://rips-irsp.com/articles/10.5334/irsp.90
La meilleure manière de visualiser des données
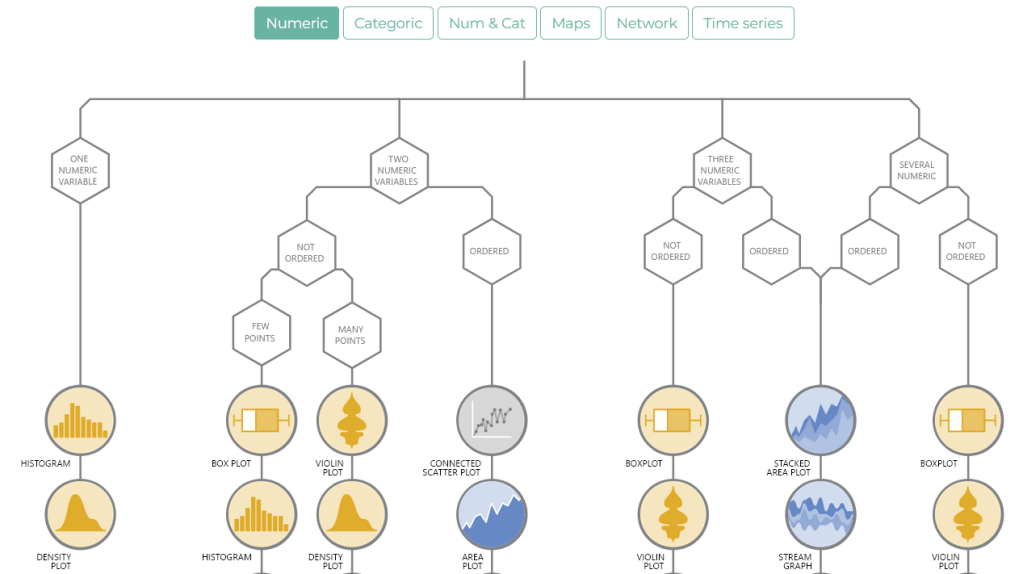
Si vous ne savez pas quelle serait la meilleure manière de présenter vos données, vous trouverez ici : https://www.data-to-viz.com/ un arbre de décision pour trouver la plus belle manière de les présenter. Vous trouverez ensuite ici : https://r-graph-gallery.com/index.html le code pour le présenter.
Meta Analysis Magic
Le blog de Matthew Jané, chercheur en statistique qui a beaucoup écrit sur les méta-analyses. Les réponses à Jon. Haidt qui a fait une méta-analyse absolument affolante de nullité sur le lien entre écran et violence est très intéressant (voir un très grand chercheur respecté se faire ridiculiser par un doctorant parce qu’il ne comprend visiblement rien aux calculs de base est assez divertissant).
https://matthewbjane.github.io/blog.html
Détection d’erreur
Si vous vous intéressez à un domaine qui me passionne, la détection d’erreur, je vous propose d’abord de lire les articles les plus lu de pubpeer : https://pubpeer.com/. Je vous recommande également le blog de Nick Brown : https://steamtraen.blogspot.com/, celui de Dorothy Bishop : https://deevybee.blogspot.com/ et enfin le cours d’analyse forensic de James Heather : https://jamesheathers.curve.space/.
Enfin, récemment a ouvert le COSIG, une collection de guides d’intégrité scientifique: https://cosig.net/
Comment faire un tableau Excel
Ressource obligatoire si vous voulez que je vous aide sur vos stats, un billet de blog clair et concis : Simple tips for recording data.
Cours
Ici, je regroupe les cours sous forme de livre, de site internet, de vidéo youtube ou de cours en ligne.
Introduction à R
Je ne connais pas de bon cours d’introduction à R en Français. Une recherche Google me propose le cours suivant : https://bookdown.org/evraloui/lbira2110/ vous aurez des ressources très intéressante sur le Blog MGTO de Gilad Feldman cité plus haut. Notez que les modèles de langage répondent correctement à toutes les questions de base sur R ou Rstudio.
Pour la visualisation de données, j’ai beaucoup utilisé ce powerpoint : https://satrdayjoburg.djnavarro.net/slides/#1
Conduire une méta-analyse
Le guide « Doing Meta-Analysis with R: A Hands-On Guide” est extrêmement complet et permet de conduire une méta-analyse du début à la fin sur R.
https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/
Si vous décidez de faire une méta-analyse psychométrique (une méta-analyse qui teste des corrélations entre échelles), tournez vous vers 1) le package Psychmeta https://cran.r-project.org/web/packages/psychmeta/vignettes/ma_r.html et 2) le guide de Matthew Jané https://matthewbjane.quarto.pub/artifact-corrections-for-effect-sizes/
Sans vouloir me faire de la pub, j’ai développé des modèles pour faire des méta-analyses. Vous les trouverez ici:
Taille d’effet et conversion
Matthew Jané, Gilad Feldman et une tripoté d’auteurs ont travaillé sur un guide complet transformant toutes les tailles d’effet en d’autres et les calculs permettant de produire des intervalles de confiance.
https://matthewbjane.quarto.pub/guide-to-effect-sizes-and-confidence-intervals/
D’une introduction à R à l’analyse approfondie des équations structurelles
Sacha Epskamp a créé une liste impressionante de viéos youtube. Vous trouverez des playlists allant des bases sur R aux pratiques les plus avancées comme les équations structurelles.
https://www.youtube.com/@Sacha_Epskamp/playlists
Repenser les statistiques
Un cours des fondamentaux des inférences statistiques de Richard McElreath.
Improve your statistical questions and inferences
Avant de sortir un livre en ligne, Daniël Lakens avait créé le cours d’amélioration des inférences statistiques (puis celui des question statistiques) sur coursera, accessibles gratuitement : https://www.coursera.org/instructor/~20199472?msockid=244264663da460020aa871703c1f6171
Pourquoi les scientifiques mentent
Une introductions aux pratiques de recherche frauduleuses et pratiques de recherche questionnables :
https://howscientistslie.com/index.html
Linux
Puisque Windows a décidé de jouer à être les méchants de l’histoire, je suis passé à linux et je suis toujours vivant. Ici, un guide qui permet d’apprendre les raccourcis du terminal linux en ligne sans rien installer : https://www.webterm.app/en
Idée pour la suite :
Podcast
RTS
Mon Podcast avec Nathanaël Larigaldie. Le seul podcast meta-science en Français :
Nullius in Verbas
Podcast de Daniël Lakens : l’essence de la méta-science.
Everything Hertz
Un Podcast animé par Daniel Quintana avec James Heather, un des principaux noms de la détection d’erreur
2 psychologists 4 beers
Yoel Inbar et Michael Inzlicht discutent de l’actualité de la psychologie en buvant des bières.
Decoding The GURU
Un podcast qui utilise l’esprit critique et la science pour débunker des croyances, et des gouroux.
Package R
Mes packages préférés en vrac :
« tidyverse », « ggplot2 », « knitr », « lme4 », « afex », « performance », « lmerTest », « arm », « lattice », « plotly », « ggthemes », « ltm », « table1 », « stargazer », « effects », « pandoc », « interactions », « jtools », « modelsummary », « emmeans », « sjPlot »
orchaRd 2.0 : visualisation de méta-analyse : https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14152
ggdist : visualisation de distributions : https://mjskay.github.io/ggdist/
Compare Whiz : comparer tout : https://marton-l-gy.shinyapps.io/StatCompare-Whiz/
hrbrt themes : changer la police des ggplot : https://github.com/hrbrmstr/hrbrthemes
SJPlot
https://strengejacke.github.io/sjPlot/
GGstatplot
https://indrajeetpatil.github.io/ggstatsplot/index.html
Livres
Improving your statistical inferences
C’est le livre qui accompagne le billet de blog de Daniël Lakens. Daniël y explique les bonnes pratiques de recherche pour à peu près tout, que cela soit l’utilisation de la p-valeur, la méta-analyse, la détection de biais, le pré-enregistrement etc.
https://lakens.github.io/statistical_inferences/
Book of why
Un livre fondamental pour comprendre comment fonctionne les rapports de causalité et arrêter enfin avec le « attention, corrélation n’est pas causalité » qui n’a aucun sens. A noter que je vous partage un lien pour prendre le livre gratuitement, l’auteur étant pro-israëlien et soutenant l’armée Israëlienne
Doctored
Un livre retraçant l’histoire entière derrière la fraude massive des laboratoires travaillant sur l’hypothèse amyloïde d’alzheimer.
https://www.simonandschuster.com/books/Doctored/Charles-Piller/9781668031247
Science fictions
Un livre par Stuart Richie faisant l’inventaire de toutes les manières qu’ont les chercheurs d’inventer des études scientifiques.
Statistical inference as severe testing
Livre très complexe et technique sur le débat actuel de l’utilisation des tests statistiques. De nombreux cours sur les tests statistiques et la philosophie de la science s’arrêtent aux années 70. Cependant, de nombreux débats sont toujours en cours, expliqués dans ce livre.

Laisser un commentaire